Johannesburg, 15 Sept 2015

Most network management products miss the point and come up short. Their primary focus is on monitoring uptime. This is often referred to as a RAG tool: Red, Amber, and Green where Red signifies down, Amber signifies intermittent connectivity problems and Green signifies good connectivity. This serves a limited business purpose and cannot justify any return on investment. Product development focussed on reporting on acceptable situations, as opposed to providing equal focus on a network in dire straits. How is this monitoring? All it does is give you a comfortable feeling. With this approach there is no difference in the value proposition of 'ping' or a network management framework product using SNMP worth millions.
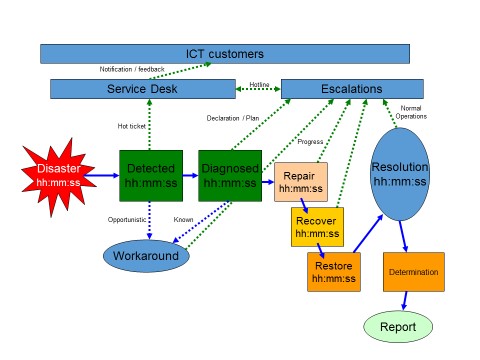
What is required is to monitor downtime. Outages should be reported on from an outage timeline perspective and aggregated to provide a pattern or trend. It is not the length of time of the outage that is important but the crucial time periods within the outage that provide the metrics. These metric times are aligned with ITIL's expanded incident lifecycle.
There is an industry wide infatuation with "9's". Where is the real worth in reporting 99.9% availability? This translates to 0.1% outages but even this has limited meaning as:
- We cannot ascertain which services as opposed to which devices were affected
- We are unable to establish the business impact and resulting consequences
- We don't have insight into the prevailing conditions during the outage
- The resolution or temporary fix is unknown
- The visual, proximate and root causes should have been annotated
- We don't know the resources assigned to work on the outage
- The outage classification and prioritisation is unknown and we are unable to assess the risk and mitigating actions
A metric of 0.1% answers none of these questions and no network management product in existence answers the above questions in a suitable manner. As an example, does a historical snapshot exist of other outages at a certain time of a major incident where there have been severe negative business consequences?
Crucially, the monitoring of downtime needs to record the delta in the time when the actual outage happened against when the outage was acknowledge and escalated to the responsible operator via a notification process. If there was an outage with no notification, this needs to appear in an exception report.
Every network management product vendor bases their sales pitch on the fact that they will provide a faster detection time for an outage. This is pure koolaid as the reason in most cases, when the downtime of an outage is analysed, the detection time is the smallest contribution to the overall length of the outage downtime. Why would anyone buy a tool that's primary purpose is to address the smallest requirement?
Another misnomer is that a monitoring tool will somehow miraculously prevent an outage. The reality is that Significant Havoc in Technology happens, and if your tool is only focused on prevention, it will fail when you try to use it to cure. The value of a tool is in how it deals with an outage, because the reality is that the HOW is the major factor in dealing with service improvements. Optimal management of outages results in two trends:
- the time period between outages increases
- the length of the outage reduces
There is no value in your monitoring tool if it cannot influence these trends and worse, if it cannot report on or measure them.
The next step is diagnosis. Diagnosis monitoring is not that difficult. What often happens is that an outage occurs; an engineer diagnoses the issue and after initial investigation, proposes a solution. Often this knowledge remains in the engineer's head and is not recorded or annotated in a knowledge base. If this practise of recording incidents and their resulting resolutions was consistently done, then the diagnosis time of an incident would consistently reduce. Immediately a tool that provides this ability would have a justifiable return on investment.
The repair-recovery-restore time periods are not difficult to measure if a network management product is service aware, as these metric times will be obvious.
In order to be of value, the output required is an analysis of the consequences of downtime:
- what is the total outage time and what was the time period of degradation (brown outs versus black outs)
- what is the deviation from the norm for this outage compared against the historical trend data
- what are the average incident times for: detection, diagnosis, repair, recover and restore
- what are the top services affected by outages
- what are the top causes of outages
- what is the MTTR, MTBF and MTBSI
There are many possible causes of extended downtime periods. How does a RAG (Red-Amber-Green) tool help to assist in resolving?
- Long detection times or even misses
- Diagnostics.
- Logistic issues delaying repair.
- Slow recovery, like having to rebuild from scratch as there is no known last configuration.
- Slow return to service even though the device is recovered.
- No workarounds being available or documented.
- Network management needs to step up a gear from the current RAG mindset-it really isn't about the traffic lights, but actually driving the vehicle!
Share