How much is database downtime really costing you?
How much does downtime cost?
A bit of Googling will give you several different answers to this question; and while each answer needs to be taken with a pinch of salt, they are all equally terrifying.
Reports created between 2014 and 2019 cite that a mere 60 seconds of IT downtime can cost a large organisation between R65,000 and R100,000. Scary, right? A typical SLA response time is 15min, and if it takes an engineer another hour, the costs can quickly mount up.
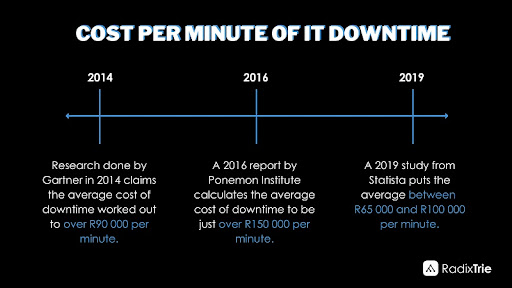
For small and medium-sized businesses, that figure drops to between R2,000 and R7,000 per minute; an easier amount to swallow, but still unaffordable for small corporations.
But if we’re talking databases, what elements go into the calculation of the direct cost of downtime?
● Revenue lost while the e-commerce database was down: ((Gross annual revenue / days per year open) / hours per day open for business) = Estimated revenue loss per hour.
● Lost productivity of staff unable to work: (Number of employees * average employee wage per hour) * average % of lost productivity = Total labour cost per hour.
● Cost of data loss and the cost of recovering it (all, or only some): Data recovery specialist cost per hour + unforeseen costs of not being able to recover all of the data = Cost of data recovery and loss.
● Wasted marketing spend: (Total marketing campaign spend / hours in campaign) * hours spend offline = wasted marketing spend.
● Cost of missed SLA commitments: Missed SLAs can lead to penalties, plus the damage to your reputation as a service provider.
On top of this are the indirect costs that are harder to calculate. This includes things like the reputation damage sustained while your customers couldn’t access their data, the revenue from potential customers who will now choose one of your competitors, or the stress placed on your poor DBAs whilst trying to save the day.
What are the different types of database downtime?
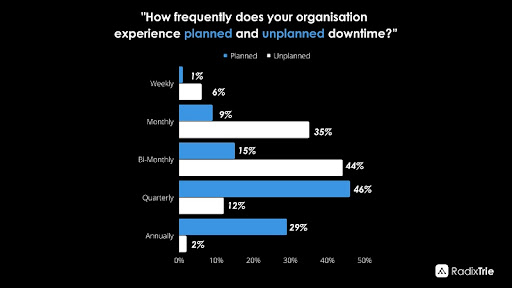
Downtime can be categorised as either planned or unplanned.
As the name suggests, planned downtime is scheduled and is used to perform upgrades or make configuration changes. Unplanned downtime, on the other hand, comes out of the blue and can be caused by incorrect or lack of database maintenance, expensive database queries that degrade database performance, infrastructure failures, failed backups, or worse - an unknown error.
While both forms can be costly, unplanned downtime is the more expensive of the two. In August 2019, IBM commissioned a study of 100 IT directors in large enterprises across the United States. The study found that, on average, unplanned downtime costs 35% more than its planned counterpart.
So how much does downtime really cost? Too much.
How do I prepare my team to deal with database downtime?
The unfortunate reality is that downtime does happen. However, with proper database maintenance, you can decrease the chances and frequency of downtime.
How do you prepare your teams to deal with a crisis when it inevitably strikes?
Imagine a scenario where one of your most critical databases suddenly stops working.
A user has tried to log on to your application several times without success and calls to complain (if you don’t have a monitoring system in place, that is). Someone from your team quickly logs a ticket with a note that the issue is urgent.
Your Service Desk team needs to assign the ticket to the correct person. For this, an initial investigation is required, and the issue appears to be server-related, so they assign the ticket to the resident server expert on call.
Their investigation shows that the real problem lies within the database, so they reassign the ticket to one of the DBAs.
Eventually, after a significant amount of bouncing back and forth, the ticket lands with the correct DBA, and they can begin to investigate the issue.
Bear in mind that while all this has been happening, more and more of your users are having issues and calling to complain, but no work on fixing the issue has even begun…
Database continuity management is key. You need to have a plan in place to map out elements, such as:
● Which databases are the most important, and do they have high-availability and disaster recovery measures in place?
● If all redundancy measures fail, how long will it take to restore from backups, and what will be the business impact?
● Which database management and monitoring tools are critical, and what will be the impact if they are not available?
● Do we have standard processes for the initial investigation to identify the root cause and are these actively exercised?
● Will the engineers be able to connect remotely, and is connection redundancy in place?
● Is the database being actively monitored for all downtime scenarios, and will the correct people be notified?
Clear communication lines, thoroughly planned policies, and well-informed team members can streamline this process and can save your organisation thousands of Rands amid a crisis.
But, if you want to minimise the chances of a P1 situation even happening, you’ll need to do significant hard work before the fact – like planning for different scenarios.
How can I get 100% database uptime?
100% availability and stability simply isn’t economically plausible, for now, but it might be on the horizon thanks to smart database practices.
Gerhard Pieters, a Senior Database Administrator at RadixTrie suggests that proactive monitoring is the first place to start.
"Closely monitoring your databases in real-time and performing daily (and ad hoc) checks can help you spot anomalies before they become problematic,”
“In your daily checks, look out for things like internal and external resource utilisation, database background processes, long-running statements, and connections, database, and server logs, wait events, etc. Setting baselines and KPIs for these makes it easier to capture anomalies or trends in the wrong direction."
“We have witnessed a significant decrease in database downtime with numerous customers when databases are deployed on database appliances. Hardware and software that are engineered to work together is more expensive but seems to deliver on the promises when implemented by experts.”

Coupled with this, Pieters says that correctly setting up your infrastructure and the relentless implementation of best practices can help mitigate downtime as possible.
“Always strive to apply best practices in your environment in relation to high-availability architecture, disaster recovery measures, database upgrades, performance, patching, motoring, root cause analysis, and troubleshooting,”
“However, understanding and implementing best practices involve a lot of time and expertise. If your team does not have the necessary experience, consider reaching out to seasoned professionals, as they are always the best choice.”